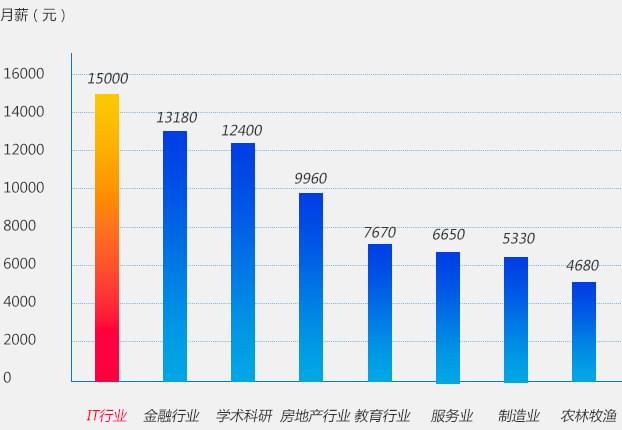
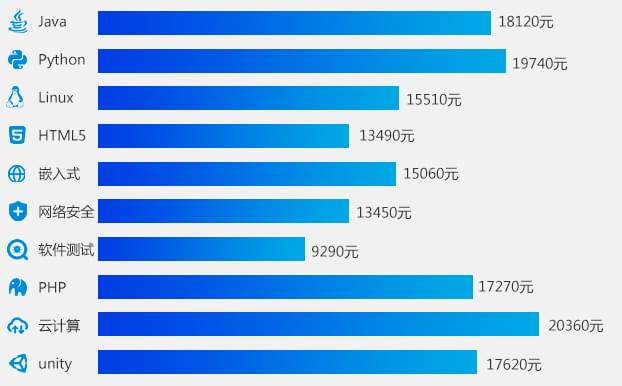
IT行业均薪领跑7大传统行业
去年各行业月收入对比
今年IT各技术方向行业平均薪资
IT培训网面向所有课程学员提供先就业后付款学习方案,保证学员稳定就业,可谓0学费!免除学习压力。
正文:
使用 .NET 5 体验大数据和机器学习,.net的作用还是蛮大的,学习.net未来还是蛮有发展的!
.NET 5 旨在提供统一的运行时和框架,使其在各平台都有统一的运行时行为和开发体验。微软发布了与 .NET 协作的大数据(.NET for Spark)和机器学习(ML.NET)工具,这些工具共同提供了富有成效的端到端体验。在本文中,我们将介绍 .NET for Spark、大数据、ML.NET 和机器学习的基础知识,我们将研究其 API 和功能,向你展示如何开始构建和消费你自己的 Spark 作业和 ML.NET 模型。
什么是大数据
大数据是一个几乎不言自明的行业术语。该术语指的是大型数据集,通常涉及 TB 甚至 PB 级的信息,这些数据集被用作分析的输入,以揭示数据中的模式和趋势。大数据与传统工作负载之间的关键区别在于,大数据往往过于庞大、复杂或多变,传统数据库和应用程序无法处理。一种流行的数据分类方式被称为 "3V"(译注:即3个V,Volume 容量、Velocity 速度、Variety 多样性)。
大数据解决方案是为适应高容量、处理复杂多样的数据结构而定制的,并通过批处理(静态)和流处理(动态)来管理速度。
大多数大数据解决方案都提供了在数据仓库中存储数据的方式,数据仓库通常是一个为快速检索和为并行处理而优化的分布式集群。处理大数据往往涉及多个步骤,如下图所示:

.NET 5 开发人员如果需要基于大型数据集进行分析和洞察,可以使用基于流行的大数据解决方案 Apache Spark 的 .NET 实现:.NET for Spark。
.NET for Spark
.NET for Spark 基于 Apache Spark,这是一个用于处理大数据的开源分析引擎。它被设计为在内存中处理大量数据,以提供比其他依赖持久化存储的解决方案更好的性能。它是一个分布式系统,并行处理工作负载。它为加载数据、查询数据、处理数据和输出数据提供支持。
Apache Spark 支持 Java、Scala、Python、R 和 SQL。微软创建了 .NET for Spark 以增加对 .NET 的支持。该解决方案提供了免费、开放、跨平台的工具,用于使用 .NET 所支持的语言(如 C#和 F#)构建大数据应用程序,这样你就可以使用现有的 .NET 库,同时利用 SparkSQL 等 Spark 特性。

以下代码展示了一个小而完整的 .NET for Spark 应用程序,它读取一个文本文件并按降序输出字数。
在开发机器上配置 .NET for Spark 需要安装几个依赖,包括 Java SDK 和 Apache Spark。你可以在这里(https://aka.ms/go-spark-net)查看手把手的入门指南。
Spark for .NET 可在多种环境中运行,并可部署到云中运行。可部署目标包括 Azure HDInsight、Azure Synapse、AWS EMR Spark 和 Databricks 等。如果数据作为项目可用的一部分,你可以将其与其他 project 文件一起提交。
大数据通常与机器学习一起使用,以获得关于数据的洞察。
什么是机器学习
首先,我们先来介绍一下人工智能和机器学习的基本知识。
人工智能(AI)是指计算机模仿人类智慧和能力,如推理和寻找意义。典型的人工智能技术通常是从规则或逻辑系统开始的。作为一个简单的例子,想一想这样的场景:你想把某样东西分类为“面包”或“不是面包”。当你开始时,这似乎是一个简单的问题,例如“如果它有眼睛,它就不是面包”。然而,你很快就会开始意识到,有很多不同的特征可以将某物定性为面包与非面包,而且特征越多,一系列的 if 语句就会越长越复杂,如下图所示:

从上图中的例子可以看出,传统的、基于规则的人工智能技术往往难以扩展。这就是机器学习的作用。机器学习(ML)是人工智能的一个子集,它能在过去的数据中找到模式,并从经验中学习,以对新数据采取行动。ML 允许计算机在没有明确的逻辑规则编程的情况下进行预测。因此,当你有一个难以(或不可能)用基于规则的编程解决的问题时,你可以使用 ML。你可以把 ML 看作是 "对不可编程的编程"。
为了用 ML 解决“面包”与“非面包”的问题,你提供面包的例子和非面包的例子(如下图所示),而不是实现一长串复杂的 if 语句。你将这些例子传递给一个算法,该算法在数据中找到模式,并返回一个模型,然后你可以用这个模型来预测尚未被模型“看到”的图像是“面包”还是“不是面包”。

上图展示了 AI 与 ML 的另一种思考方式。AI 将规则和数据作为输入,预期输出基于这些规则的答案。而 ML 则是将数据和答案作为输入,输出可用于对新数据进行归纳的规则。

AI 将规则和数据作为输入,并根据这些规则输出预期的答案。ML 将数据和答案作为输入,并输出可用于概括新数据的规则。
ML.NET
微软在 2019 年 5 月的 Build 上发布了 ML.NET,这是一个面向.NET 开发人员的开源、跨平台 ML 框架。在过去的九年里,微软的团队已经广泛使用该框架的内部版本来实现流行的 ML 驱动功能;一些例子包括 Dynamics 365 欺诈检测、PowerPoint 设计理念和 Microsoft Defender 防病毒威胁保护。
ML.NET 允许你在.NET 生态系统中构建、训练和消费 ML 模型,而不需要 ML 或数据科学的背景。ML.NET 可以在任何.NET 运行的地方运行。Windows、Linux、macOS、on-prem、离线场景(如 WinForms 或 WPF 桌面应用)或任何云端(如 Azure)中。你可以将 ML.NET 用于各种场景,如表 1 所述。
ML.NET 使用自动机器学习(或称 AutoML)来自动构建和训练 ML 模型的过程,以根据提供的场景和数据找到最佳模型。你可以通过 AutoML.NET API 或 ML.NET 工具来使用 ML.NET 的 AutoML,其中包括 Visual Studio 中的 Model Builder 和跨平台的 ML.NET CLI,如图 6 所示。除了训练最佳模型外,ML.NET 工具还生成在最终用户.NET 应用程序中消费模型所需的文件和 C#代码,该应用程序可以是任何.NET 应用程序(桌面、Web、控制台等)。所有 AutoML 方案都提供了本地训练选项,图像分类也允许你利用云的优势,使用 Model Builder 中的 Azure ML 进行训练。

你可以在 Microsoft Docs 中了解更多关于 ML.NET 的信息,网址是:https://aka.ms/mlnetdocs。
ML 和大数据结合
大数据和 ML 可以很好地结合在一起。让我们构建一个同时使用 Spark for .NET 和 ML.NET 的管道,以展示大数据和 ML 如何一起工作。Markdown 是一种用于编写文档和创建静态网站的流行语言,它使用的语法不如 HTML 复杂,但提供的格式控制比纯文本更多。这是从 .NET 文档库中的摘取一段 markdown 文件内容:
破折号之间的部分称为前页(front matter),是使用 YAML 描述的有关文档的元数据。以井号(#)开头的部分是标题。两个哈希(##)表示二级标题。“ .NET Core 入门”是一个超链接。
我们的目标是处理大量文档,添加诸如字数和估计的阅读时间之类的元数据,并将相似的文章自动分组在一起。
这是我们将构建的管道:
为每个文档建立字数统计;
估计每个文档的阅读时间;
根据“ TF-IDF”或“术语频率/反向文档频率”为每个文档创建前 20 个单词的列表(这将在后面说明)。
第一步是拉取文档存储库和需引用的应用程序。你可以使用任何包含 Markdown 文件的存储库及文件夹结构。本文使用的示例来自 .NET 文档存储库,可从 https://aka.ms/dot-net-docs 克隆。
为.NET 和 Spark 准备本地环境之后,可以从https://aka.ms/spark-ml-example拉取项目。
解决方案文件夹包含一个批处理命令(在仓库中有提供),你可以使用该命令来运行所有步骤。
处理 Markdown
DocRepoParser 项目以递归方式遍历存储库中的子文件夹,以收集各文档有关的元数据。Common 项目包含几个帮助程序类。例如,FilesHelper 用于所有文件 I/O。它跟踪存储文件和文件名的位置,并提供诸如为其他项目读取文件的服务。构造函数需要一个标签(一个唯一标识工作流的数字)和包含文档的 repo 或顶级文件夹的路径。默认情况下,它在用户的本地应用程序数据文件夹下创建一个文件夹。如有必要,可以将其覆盖。
MarkdownParser利用 Microsoft.Toolkit.Parsers解析 Markdown 的库。该库有两个任务:首先,它必须提取标题和子标题;其次,它必须提取单词。Markdown 文件以 "块 "的形式暴露出来,代表标题、链接和其他 Markdown 特征。块又包含承载文本的“Inlines”。例如,这段代码通过迭代行和单元格来解析一个 TableBlock,以找到 Inlines。
此代码提取超链接的文本部分:
结果是一个 CSV 文件,如下图所示:

第一步只是准备要处理的数据。下一步使用 Spark for .NET 作业确定每个文档的字数,阅读时间和前 20 个术语。
构建 Spark Job
SparkWordsProcessor项目用来运行 Spark 作业。虽然该应用程序是一个控制台项目,但它需要 Spark 来运行。runjob.cmd批处理命令将作业提交到正确配置的 Windows 计算机上运行。典型作业的模式是创建一个会话或“应用程序”,执行一些逻辑,然后停止会话。
var spark = SparkSession.Builder() .AppName(nameof(SparkWordsProcessor)) .GetOrCreate(); RunJob(); spark.Stop();
通过将其路径传递给 Spark 会话,可以轻松读取上一步的文件。
var docs = spark.Read().HasHeader().Csv(filesHelper.TempDataFile); docs.CreateOrReplaceTempView(nameof(docs)); var totalDocs = docs.Count();
docs变量解析为一个DataFrame。Data Frame 本质上是一个带有一组列和一个通用接口的表,用于与数据交互,而不管其底层来源是什么。可以从其他 data frame 中引用一个 data frame。SparkSQL 也可以用来查询 data frame。你必须创建一个临时视图,该视图为 data frame 提供别名,以便从 SQL 中引用它。通过CreateOrReplaceTempView方法,可以像这样从 data frame 中查询行:
SELECT * FROM docs
totalDocs变量检索文档中所有行的计数。Spark 提供了一个名为Split的将字符串分解为数组的函数。Explode函数将每个数组项变成一行:
var words = docs.Select(fileCol, Functions.Split(nameof(FileDataParse.Words) .AsColumn(), " ") .Alias(wordList)) .Select(fileCol, Functions.Explode(wordList.AsColumn()) .Alias(word));
该查询为每个单词或术语生成一行。这个 data frame 是生成术语频率(TF)或者说每个文档中每个词的计数的基础。
var termFrequency = words .GroupBy(fileCol, Functions.Lower(word.AsColumn()).Alias(word)) .Count() .OrderBy(fileCol, count.AsColumn().Desc());
Spark 有内置的模型,可以确定“术语频率/反向文档频率”。在这个例子中,你将手动确定术语频率来演示它是如何计算的。术语在每个文档中以特定的频率出现。一篇关于 wizard 的文档可能有很高的“wizard”一词计数。同一篇文档中,"the "和 "is "这两个词的出现次数可能也很高。对我们来说,很明显,“wizard”这个词更重要,也提供了更多的语境。另一方面,Spark 必须经过训练才能识别重要的术语。为了确定什么是真正重要的,我们将总结文档频率(document frequency),或者说一个词在 repo 中所有文档中出现的次数。这就是“按不同出现次数分组”:
var documentFrequency = words .GroupBy(Functions.Lower(word.AsColumn()) .Alias(word)) .Agg(Functions.CountDistinct(fileCol) .Alias(docFrequency));
现在是计算的时候了。一个特殊的方程式可以计算出所谓的反向文档频率(inverse document frequency),即 IDF。将总文档的自然对数(加一)输入方程,然后除以该词的文档频率(加一)。
static double CalculateIdf(int docFrequency, int totalDocuments) => Math.Log(totalDocuments + 1) / (docFrequency + 1);
在所有文档中出现的词比出现频率较低的词赋值低。例如,给定 1000 个文档,一个在每个文档中出现的词与一个只在少数文档中出现的词(约 1 个)相比,IDF 为 0.003。Spark 支持用户定义的函数,你可以这样注册。
spark.Udf().Register
接下来,你可以使用该函数来计算 data frame 中所有单词的 IDF:
var idfPrep = documentFrequency.Select(word.AsColumn(), docFrequency.AsColumn()) .WithColumn(total, Functions.Lit(totalDocs)) .WithColumn(inverseDocFrequency, Functions.CallUDF(nameof(CalculateIdf), docFrequency.AsColumn(), total.AsColumn() ) );
使用文档频率 data frame,增加两列。第一列是文档的单词总数量,第二列是调用你的 UDF 来计算 IDF。还有一个步骤,就是确定“重要词”。重要词是指在所有文档中不经常出现,但在当前文档中经常出现的词,用 TF-IDF 表示,这只是 IDF 和 TF 的产物。考虑“is”的情况,IDF 为 0.002,在文档中的频率为 50,而“wizard”的 IDF 为 1,频率为 10。相比频率为 10 的“wizard”,“is”的 TF-IDF 计算结果为 0.1。这让 Spark 对重要性有了更好的概念,而不仅仅是原始字数。
到目前为止,你已经使用代码来定义 data frame。让我们尝试一下 SparkSQL。为了计算 TF-IDF,你将文档频率 data frame 与反向文档频率 data frame 连接起来,并创建一个名为termFreq_inverseDocFreq的新列。下面是 SparkSQL:
var idfJoin = spark.Sql($"SELECT t.File, d.word, d.{docFrequency}, d.{inverseDocFrequency}, t.count, d.{inverseDocFrequency} * t.count as {termFreq_inverseDocFreq} from {nameof(documentFrequency)} d inner join {nameof(termFrequency)} t on t.word = d.word");
探索代码,看看最后的步骤是如何实现的。这些步骤包括:
到目前为止所描述的所有步骤都为 Spark 提供了一个模板或定义。像 LINQ 查询一样,实际的处理在结果被具体化之前不会发生(比如计算出总文档数时)。最后一步调用 Collect 来处理和返回结果,并将其写入另一个 CSV。然后,你可以使用新文件作为 ML 模型的输入,下图是该文件的一部分:

Spark for .NET 使你能够查询和塑造数据。你在同一个数据源上建立了多个 data frame,然后添加它们以获得关于重要术语、字数和阅读时间的洞察。下一步是应用 ML 来自动生成类别。
预测类别
最后一步是对文档进行分类。DocMLCategorization项目包含了 ML.NET 的Microsoft.ML包。虽然 Spark 使用的是 data frame,但 data view 在 ML.NET 中提供了类似的概念。
这个例子为 ML.NET 使用了一个单独的项目,这样就可以将模型作为一个独立的步骤进行训练。对于许多场景,可以直接从你的.NET for Spark 项目中引用 ML.NET,并将 ML 作为同一工作的一部分来执行。
首先,你必须对类进行标记,以便 ML.NET 知道源数据中的哪些列映射到类中的属性。在FileData 类使用 LoadColumn 注解,就像这样:
[LoadColumn(0)] public string File { get; set; } [LoadColumn(1)] public string Title { get; set; }
然后,你可以为模型创建上下文,并从上一步中生成的文件中加载 data view:
var context = new MLContext(seed: 0); var dataToTrain = context.Data .LoadFromTextFile
ML 算法对数字的处理效果最好,所以文档中的文本必须转换为数字向量。ML.NET 为此提供了FeaturizeText方法。在一个步骤中,模型分别:
检测语言
将文本标记为单个单词或标记
规范化文本,以便对单词的变体进行标准化和大小写相似化
将这些术语转换为一致的数值或准备处理的“特征向量”
以下代码将列转换为特征,然后创建一个结合了多个特征的“Features”列。
var pipeline = context.Transforms.Text.FeaturizeText( nameof(FileData.Title).Featurized(), nameof(FileData.Title)).Append(context.Transforms.Text.FeaturizeText(nameof(FileData.Subtitle1).Featurized(), nameof(FileData.Subtitle1))).Append(context.Transforms.Text.FeaturizeText(nameof(FileData.Subtitle2).Featurized(), nameof(FileData.Subtitle2))).Append(context.Transforms.Text.FeaturizeText(nameof(FileData.Subtitle3).Featurized(), nameof(FileData.Subtitle3))).Append(context.Transforms.Text.FeaturizeText(nameof(FileData.Subtitle4).Featurized(), nameof(FileData.Subtitle4))).Append(context.Transforms.Text.FeaturizeText(nameof(FileData.Subtitle5).Featurized(), nameof(FileData.Subtitle5))).Append(context.Transforms.Text.FeaturizeText(nameof(FileData.Top20Words).Featurized(), nameof(FileData.Top20Words))).Append(context.Transforms.Concatenate(features, nameof(FileData.Title).Featurized(), nameof(FileData.Subtitle1).Featurized(), nameof(FileData.Subtitle2).Featurized(), nameof(FileData.Subtitle3).Featurized(), nameof(FileData.Subtitle4).Featurized(), nameof(FileData.Subtitle5).Featurized(), nameof(FileData.Top20Words).Featurized()) );
此时,数据已经为训练模型做了适当的准备。训练是无监督的,这意味着它必须用一个例子来推断信息。你没有将样本类别输入到模型中,所以算法必须通过分析特征如何聚类来找出数据的相互关联。你将使用k-means 聚类算法。该算法使用特征计算文档之间的“距离”,然后围绕分组后的文档“绘制”边界。该算法涉及随机化,因此两次运行结果会是不相同的。主要的挑战是确定训练的最佳聚类大小。不同的文档集最好有不同的最佳类别数,但算法需要你在训练前输入类别数。
代码在 2 到 20 个簇之间迭代,以确定最佳大小。对于每次运行,它都会获取特征数据并应用算法或训练器。然后,它根据预测模型对现有数据进行转换。对结果进行评估,以确定每个簇中文档的平均距离,并选择平均距离最小的结果。
var options = new KMeansTrainer.Options { FeatureColumnName = features, NumberOfClusters = categories, }; var clusterPipeline = pipeline.Append(context.Clustering.Trainers.KMeans(options)); var model = clusterPipeline.Fit(dataToTrain); var predictions = model.Transform(dataToTrain); var metrics = context.Clustering.Evaluate(predictions); distances.Add(categories, metrics.AverageDistance);
经过培训和评估后,你可以保存最佳模型,并使用它对数据集进行预测。将生成一个输出文件以及一个摘要,该摘要显示有关每个类别的一些元数据并在下面列出标题。标题只是几个功能之一,因此有时需要仔细研究细节才能使类别有意义。在本地测试中,教程之类的文档归于一组,API 文档归于另一组,而例外归于它们自己的组。
ML zip 文件可与 Prediction Engine 一起用于其他项目中的新数据。
机器学习模型另存为单个 zip 文件。该文件可以包含在其他项目中,与 Prediction Engine 一起使用以对新数据进行预测。例如,你可以创建一个 WPF 应用程序,该应用程序允许用户浏览目录,然后加载并使用经过训练的模型对文档进行分类,而无需先对其进行训练。
下一步是什么
Spark for .NET 计划与.NET 5 同时在 GA(译注:GA=General Availability,正式发布的版本)发布。请访问 https://aka.ms/spark-net-roadmap 阅读路线图和推出功能的计划。(译注:.NET 5 正式发布时间已过,Spark for .NET 已随 .NET 5 正式发布)
本文着重于本地开发体验,为了充分利用大数据的力量,你可以将 Spark 作业提交到云中。有各种各样的云主机可以容纳 PB 级数据,并为你的工作负载提供数十个核的计算能力。Azure Synapse Analytics 是一项 Azure 服务,旨在承载大量数据,提供用于运行大数据作业的群集,并允许通过基于图表的仪表盘进行交互式探索。若要了解如何将 Spark for .NET 作业提交到 Azure Synapse,请阅读官方文档(https://aka.ms/spark-net-synapse)。
下面这张表列举了 ML.NET 机器学习的常见任务和场景:

姓名: 耿*琪
学历: 本科
专业: 计算机科学与技术
薪资: 16000
入职单位:非凡**科技
数据来自学员真实就业
拒绝以偏概全
| 姓名 | 学历 | 入职单位 | 专业 | 薪水 | 福利 |
| 耿*琪 | 本科 | 非凡**科技 | 计算机科学与技术 | 16000 | 五险一金 |
| 王*腾 | 本科 | 家*网 | 其他 | 17000 | 五险一金 |
| 霍*杰 | 本科 | 北京**科技有限公司 | 信息工程学院 | 17000 | 五险一金 |
| 胡*宇 | 本科 | 理*家 | 物理与电子学院 | 16000 | 五险一金 |
| 黄*正 | 本科 | 北京***人工智能科技 | 其他 | 16000 | 五险一金 |
| 张* | 本科 | 北京**互动科技 | 机械制造及自动化 | 15000 | 五险一金 |
| 佟* | 本科 | 金**团 | 理学院 | 16000 | 五险一金 |
| 刘*东 | 专科 | 保密 | 信息工程系 | 12000 | 五险一金 |
| 左*飞 | 专科 | 北京**数据 | 计算机专业 | 13000 | 五险一金 |
| 李*申 | 本科 | 汇**宇 | 计算机专业 | 12000 | 五险一金 |
| 李* | 本科 | 北京**科技 | 其他 | 13000 | 五险一金+14薪 |
| 倪* | 本科 | 保密 | 理学与信息科学学院 | 12000 | 五险一金 |
| 宋*飞 | 本科 | 腾信**科技 | 城市建设 | 13500 | 五险一金 |
| 段*阳 | 本科 | 某医疗行业 | 经济与管理工程系 | 10000 | 五险一金 |
| 文*盛 | 本科 | 保密 | 计算机专业 | 12000 | 五险一金 |
| 陈*华 | 专科 | 北京**有限公司 | 计算机软件工程系 | 12000 | 五险一金 |
| 李*腾 | 本科 | 保密 | 信息科学技术学院 | 10000 | 五险一金 |
| 郭*嘉 | 本科 | 保密 | 信息工程学院 | 13000 | 五险一金 |
| 刘*强 | 本科 | 瑞**技 | 计算机与信息技术学院 | 13000 | 五险一金 |
| 房*飞 | 本科 | 保密 | 外国语学院 | 13000 | 五险一金 |
| 吕*文 | 专科 | 和*贷 | 机械工程系 | 12000 | 五险一金 |
| 樊* | 本科 | 腾信**科技 | 河北北方学院 | 14000 | 五险一金 |
| 陈*雨 | 专科 | 瑞**技 | 测绘学院 | 12000 | 五险一金 |
| 孙* | 专科 | 保密 | 商贸系 | 10000 | 五险一金 |
想要体验大数据和机器学习 可以用使用.NET5吗
在乎每一位学员的职业梦想,坚持教育初心
| 20000名 年培养学员 |
5000名 同期在校学员 |
16城 培训中心遍布全国 |
20个 开设培训中心 |
| 500所 合作院校 |
10000家 合作企业 |
12门 目前开设课程 |
200位 讲师团队 |

· 就业保障体系覆盖全国,
· 10000多家合作企业定期招聘,
· 学员就业可随心选择。
· 全国各校区讲师统一管理,招聘标准一致,
· 课程大纲全范围内定期升级更新,
· 保障学员学习质量

 HTML5
HTML5 Java
Java Python
Python 全链路设计
全链路设计 云计算
云计算 软件测试
软件测试 大数据
大数据 智能物联网
智能物联网 Unity游戏开发
Unity游戏开发 网络安全
网络安全 互联网营销
互联网营销 Go语言开发
Go语言开发




 市场需求量大
市场需求量大 就业范围广
就业范围广 就业薪资高
就业薪资高 职业发展好
职业发展好 工作环境优
工作环境优