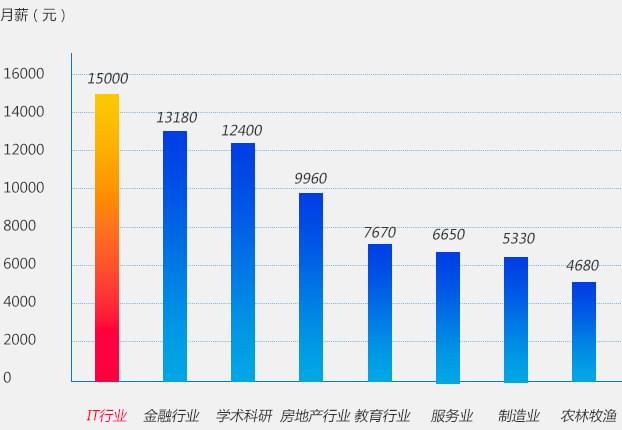
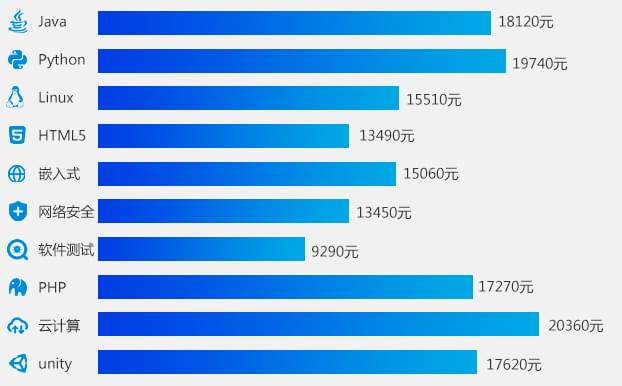
IT行业均薪领跑7大传统行业
去年各行业月收入对比
今年IT各技术方向行业平均薪资
IT培训网面向所有课程学员提供先就业后付款学习方案,保证学员稳定就业,可谓0学费!免除学习压力。
正文:
2020年值得关注的4个大数据趋势,到底在2020年什么最重要,怎么样了解大数据趋势!
在过去的几年中,我们在Redpoint投资了超过15家数据公司,并部署了超过2.5亿美元的资本。我们是数据/机器学习基础设施和分析市场的长期信奉者,并没有放缓。根据IDC的数据,全球大数据和业务分析市场在2019年达到约189B美元,预计到2022年将急剧增长至$ 274B,在此期间的复合年增长率约为13%。
这是一个令人难以置信的动态类别,我非常热衷于分析和评估接下来的工作(例如此处的数据安全性或此处的综合数据)。 我的研究旨在挖掘开创性的见解,最终帮助推动该领域的发展。 以下是我们对2020年主要四大趋势的看法:1)数据质量; 2)数据目录; 3)KPI的可观察性; 和4)流式传输。
1.数据质量
数据质量管理确保数据适合消费并满足数据使用者的需求。为了获得高质量,数据必须是一致且明确的。您可以通过包括准确性,完整性,一致性,完整性,合理性,时间表,唯一性,有效性和可访问性在内的维度来衡量数据质量。数据质量问题通常是数据库合并或系统/云集成过程的结果,在这些过程中,应兼容的数据字段不是由于架构或格式不一致引起的。不高质量的数据可以进行数据清理以提高其质量。
当前,大多数公司没有识别"脏数据"的过程或技术。通常,必须有人发现错误。然后,数据平台或工程团队必须手动识别错误并进行修复。这是一项耗时且乏味的工作(占用了数据科学家80%的时间),这也是数据科学家最抱怨的问题。
高质量的数据对于公司能否依赖它至关重要,而且不良数据的风险也很大。 尽管苛刻的观察结果"垃圾填入,垃圾填埋"困扰了几代人的分析和决策,但它对机器学习(ML)提出了特殊警告,因为开发模型所花费的时间很长。 如果ML工程师花费时间培训并提供使用不良数据构建的ML模型,则错误的ML模型将在生产中无效,并且可能对用户体验和收入产生负面的间接影响。 O'Reilly的一项调查发现,那些拥有成熟AI实践(通过生产模型的时间来衡量)的人将"缺乏数据或数据质量问题"作为阻碍进一步采用ML的主要瓶颈。
数据质量是业务人员和机器决策的基础。 脏数据可能会导致仪表板和执行人员简介中的值不正确。 此外,我们听说过糟糕的数据会导致产品开发决策,从而导致企业在工程上损失数百万美元。 基于不良数据的机器决策可能导致有偏见或不正确的行动。
> https://profisee.com/data-quality-what-why-how-who/
有一些提供数据质量解决方案的早期创业公司和开源项目。一些供应商包括Soda Data,Toro Data和Monte Carlo。
2.数据目录
根据Alation的说法,数据目录是"元数据的集合,结合了数据管理和搜索工具,可以帮助分析师和其他数据用户找到所需的数据,充当可用数据的清单,并提供评估信息。预期用途的适用性数据。"目录捕获有关数据的丰富信息,包括其应用程序上下文,行为和更改。我们对数据目录感兴趣,因为它们支持自助数据访问,从而使个人和团队受益。借助数据目录,分析师可以避免与IT部门合作来接收数据的缓慢过程,并且可以自行发现相关数据,从而提高了生产率。此外,数据目录可以通过收集有关数据使用,数据访问和PII的信息来帮助实现合规性。
有商业和开源数据目录。 商业数据目录包括Collibra,Waterline数据,Alation,Atlan,Ataccama,Zaloni,Azure数据目录,Google Cloud的数据目录,IO-Tahoe和Tamr。 Collibra在其筹款过程中最遥遥领先,最近以$ 2.3B的融资后估值筹集了$ 112.5M。 许多科技公司开放了其数据目录的来源或公开谈论它们,包括Airbnb,LinkedIn,Lyft Netflix,Spotify,Uber和WeWork。
3. KPI可观察性
大多数数据驱动型公司都利用商业智能工具(如Looker,Tableau和Superset)来跟踪关键的KPI。尽管这些操作系统可以在度量标准超过特定阈值时主动发送警报,但分析人员仍然需要深入研究细节以确定KPI为何更改。诊断仍然相当手动。
我们看到了一套新的解决方案,可以使每个企业了解推动其关键指标的因素。 运营分析平台可帮助团队超越仪表板,了解其关键指标正在发生变化的原因。 通过利用机器学习,解决方案可以确定导致KPI更改的特定因素。 我们认为,在这个领域中存在机会,因为企业需要围绕哪些基本因素提供指导。
我们将生态系统分为三类:1)异常检测/根本原因分析;2)趋势检测;和3)数据洞察力。异常通常会急剧增加/减少,并在单一度量标准级别上运行。趋势检测可捕获异常,但更重要的是可捕获基础结构的漂移和变化。数据洞察力从大量数据中发现了意外情况。
有几家公司提供KPI可观察性。 Anodot,Lightup和Orbiter专注于异常检测和引起该变化的潜在因素。 Falkon和Sisu专注于异常检测和趋势检测。 Thoughtspot SpotAI和Outlier尝试从大量数据中产生最重要的见解,而无需人工监督/配置。 在下面的展览中,我们将所有相关类别的供应商都包括在内。
4.流式传输
对企业实时决策和提供服务的需求不断增长,因此企业正在转向流式通信,存储和数据处理系统。 我们相信,随着团队继续从批处理系统转移到流系统,存在巨大的市场机会。
该领域的主要参与者是Kafka,LinkedIn于2011年开源。Kafka是一个发布-订阅系统,可提供持久,有序,可扩展的消息传递。它的体系结构包括主题,发布者和订阅者。Kafka可以划分消息主题并支持并行使用。在过去的十年中,该技术从消息传递队列演变为事件流平台。
虽然有传言说Kafka背后的公司Confluent的估值为5B美元,但我们听说该解决方案难以大规模实施和管理。 我们被告知,Zookeeper尤其难以管理,尽管该团队正在更换此组件,但可以改善用户体验。 此外,我们听说维护可能会遇到挑战,因为主题数量会迅速增加,因此团队必须一致地平衡和升级实例。
诸如Apache Pulsar之类的新流媒体方法具有两层体系结构,其中服务和存储可以分别扩展。 这对于具有无限数据保留潜力的用例来说非常重要,例如记录事件可以永久存在的情况。 此外,如果您必须存储所有消息,则不需要将所有内容都存储在高性能磁盘中。 使用Pulsar,您可以将较旧的数据移至S3,而Kafka则无法。 还有自动平衡功能,这是AWS Kinesis无法做到的。 我们还听说用户对Pulsar比Kafka更轻的客户端模型表示了同情。 除了Kafka和Flink,还有其他系统,例如NATS和Vectorized。
对于实时数据处理,Apache Flink是最着名的。 当元素出现时,Flink会对其进行处理,而不是像Spark流这样的微型批次中对其进行处理。 微批量方法的缺点是批量可能非常庞大,需要大量资源进行处理。 对于不一致或突发的数据流,这可能尤其痛苦。 Flink的另一个优点是,您无需通过反复试验就可以找到适用于微型批次的适当配置。 如果配置生成的处理时间超过其累积时间,则存在问题。 然后批次开始排队,最终所有处理都将停止。 Materialise团队还提供了更新的流引擎,例如Confluent KSQL和Timely Dataflow。
ResearchAndMarkets预测,到2023年,全球事件流处理(ESP)市场将从2018年的6.9亿美元增长到$ 1.8B,在此期间的复合年增长率为22%。 根据与买家的对话,我们认为市场的增长速度快于此。
明年,我们将关注1)数据质量的演变; 2)数据目录; 3)KPI的可观察性; 和4)流式传输。 如果您或您认识的某个人正在从事数据/ ML基础结构和分析项目或启动工作,那么很高兴收到您的来信。 您看到什么趋势? 请在下面发表评论,或通过amyers@redpoint.com给我发送电子邮件,让我们知道。
姓名: 耿*琪
学历: 本科
专业: 计算机科学与技术
薪资: 16000
入职单位:非凡**科技
数据来自学员真实就业
拒绝以偏概全
| 姓名 | 学历 | 入职单位 | 专业 | 薪水 | 福利 |
| 耿*琪 | 本科 | 非凡**科技 | 计算机科学与技术 | 16000 | 五险一金 |
| 王*腾 | 本科 | 家*网 | 其他 | 17000 | 五险一金 |
| 霍*杰 | 本科 | 北京**科技有限公司 | 信息工程学院 | 17000 | 五险一金 |
| 胡*宇 | 本科 | 理*家 | 物理与电子学院 | 16000 | 五险一金 |
| 黄*正 | 本科 | 北京***人工智能科技 | 其他 | 16000 | 五险一金 |
| 张* | 本科 | 北京**互动科技 | 机械制造及自动化 | 15000 | 五险一金 |
| 佟* | 本科 | 金**团 | 理学院 | 16000 | 五险一金 |
| 刘*东 | 专科 | 保密 | 信息工程系 | 12000 | 五险一金 |
| 左*飞 | 专科 | 北京**数据 | 计算机专业 | 13000 | 五险一金 |
| 李*申 | 本科 | 汇**宇 | 计算机专业 | 12000 | 五险一金 |
| 李* | 本科 | 北京**科技 | 其他 | 13000 | 五险一金+14薪 |
| 倪* | 本科 | 保密 | 理学与信息科学学院 | 12000 | 五险一金 |
| 宋*飞 | 本科 | 腾信**科技 | 城市建设 | 13500 | 五险一金 |
| 段*阳 | 本科 | 某医疗行业 | 经济与管理工程系 | 10000 | 五险一金 |
| 文*盛 | 本科 | 保密 | 计算机专业 | 12000 | 五险一金 |
| 陈*华 | 专科 | 北京**有限公司 | 计算机软件工程系 | 12000 | 五险一金 |
| 李*腾 | 本科 | 保密 | 信息科学技术学院 | 10000 | 五险一金 |
| 郭*嘉 | 本科 | 保密 | 信息工程学院 | 13000 | 五险一金 |
| 刘*强 | 本科 | 瑞**技 | 计算机与信息技术学院 | 13000 | 五险一金 |
| 房*飞 | 本科 | 保密 | 外国语学院 | 13000 | 五险一金 |
| 吕*文 | 专科 | 和*贷 | 机械工程系 | 12000 | 五险一金 |
| 樊* | 本科 | 腾信**科技 | 河北北方学院 | 14000 | 五险一金 |
| 陈*雨 | 专科 | 瑞**技 | 测绘学院 | 12000 | 五险一金 |
| 孙* | 专科 | 保密 | 商贸系 | 10000 | 五险一金 |
这四个大数据趋势你了解吗
在乎每一位学员的职业梦想,坚持教育初心
| 20000名 年培养学员 |
5000名 同期在校学员 |
16城 培训中心遍布全国 |
20个 开设培训中心 |
| 500所 合作院校 |
10000家 合作企业 |
12门 目前开设课程 |
200位 讲师团队 |

· 就业保障体系覆盖全国,
· 10000多家合作企业定期招聘,
· 学员就业可随心选择。
· 全国各校区讲师统一管理,招聘标准一致,
· 课程大纲全范围内定期升级更新,
· 保障学员学习质量

 HTML5
HTML5 Java
Java Python
Python 全链路设计
全链路设计 云计算
云计算 软件测试
软件测试 大数据
大数据 智能物联网
智能物联网 Unity游戏开发
Unity游戏开发 网络安全
网络安全 互联网营销
互联网营销 Go语言开发
Go语言开发




 市场需求量大
市场需求量大 就业范围广
就业范围广 就业薪资高
就业薪资高 职业发展好
职业发展好 工作环境优
工作环境优